Pytorch是一个开源深度学习框架,类似的框架还有TensorFlow, PaddlePaddle等。主要用来做深度学习模型训练和部署。
下面我们分为3个部分来介绍pytorch的基础结构和使用过程,在看之前需要了解深度学习相关的知识可以参考。
王方浩:深度学习概念整理22 赞同 · 0 评论文章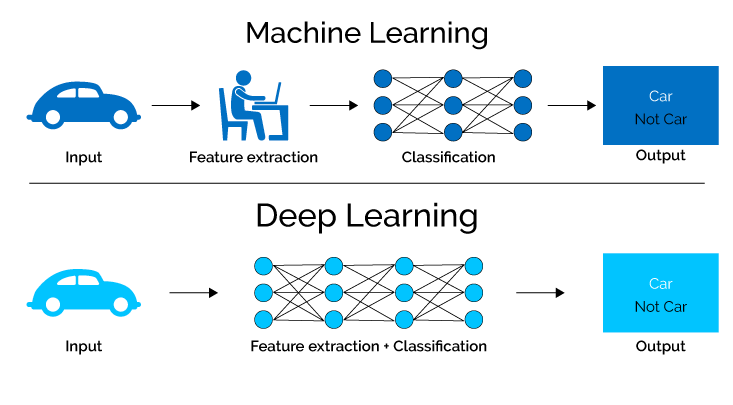
深度学习需要的基础结构可以分为:网络模型和数据2个部分。
网络模型
先构建网络模型和Loss函数,然后通过反向传播对网络做训练找到Loss最小的参数,最后保存这些参数就得到了可以工作的深度学习模型。使用的时候只要读取训练好的模型,就可以在线工作了。
1. 构建网络
pytorch中的torch.nn集成了各种网络结构,可以非常方便的构建神经网络模型,例如
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
...
def forward(self, x):
...
net = Net()
print(net)
通过继承nn.Module来创建自定义的网络模型Net,并且一定要实现以下2个接口。
__init__接口,添加自定义的网络结构。forward接口,前向传播接口,输入数据得到模型预测的结果。
完善之后的例子为
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5*5 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square, you can specify with a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1) # flatten all dimensions except the batch dimension
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)
输出的结果如下,Net网络模型包括2个卷积层和3个全连接层。
Net(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
2. Loss函数
Loss函数用来衡量网络模型的输出结果和目标值之间的差距,torch.nn定义了多种不同的Loss函数,其中最常见的是nn.MSELoss,代表输出结果和目标值的均方误差。
output = net(input) # 网络输出
target = torch.randn(10) # 目标值(值为随机生成)
target = target.view(1, -1) # make it the same shape as output
criterion = nn.MSELoss() # 均方误差Loss
loss = criterion(output, target) # 计算Loss
print(loss)
得到的结果为
tensor(0.8491, grad_fn=<MseLossBackward0>)
关于更多Loss函数的介绍可以参考Loss Functions
3. 反向传播和优化器
训练模型就是调整模型的参数,让Loss最小的过程。这个过程采用了反向传播技术,通过优化器让参数朝着Loss减少的方向调节。随机梯度下降(SGD)是最常用的优化器之一,最后通过Loss函数实现反向传播,更新参数。
import torch.optim as optim
# 创建随机梯度下降优化器
optimizer = optim.SGD(net.parameters(), lr=0.01)
# 训练过程:
optimizer.zero_grad() # 将梯度缓冲区归零
output = net(input)
loss = criterion(output, target) # 计算Loss
loss.backward() # 反向传播
optimizer.step() # 更新参数
更多关于优化器的介绍可以参考TORCH.OPTIM
数据
构建好网络之后,网络的输入是数据,pytorch同时提供了良好的数据接口,通过Dataset定义数据,通过DataLoader遍历访问数据。
1. 数据集(Dataset)
pytorch中集成了一些常用的数据集,同时用户也可以通过继承Dataset自定义数据集。
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
自定义数据集继承Dataset之后一定要实现以下2个接口
__len__接口,获取数据集的长度__getitem__通过ID获取数据集中的一条数据
2. 数据加载器(DataLoaders)
通过数据加载器加载数据的好处有:批处理数据、打乱数据和并行加载数据。下面是DataLoaders的选项。
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
dataloader = DataLoader(transformed_dataset, batch_size=4,
shuffle=True, num_workers=0)
训练流程
准备好数据和网络之后,就可以开始训练模型了,训练的过程分为train和test,其中train做训练,test做验证。
训练的过程包括3个超参数
Epochs - 迭代数据集的次数,也就是说对数据集进行了多少次迭代Batch Size - 一次训练的样本数Learning Rate - 学习率。 较小的值会导致学习速度变慢,而较大的值可能会导致训练过程中出现不可预测的行为。
learning_rate = 1e-3
batch_size = 64
epochs = 5
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
# Compute prediction and loss
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(test_dataloader, model, loss_fn)
print("Done!")
上述训练对数据集进行了10次迭代,batchsize为64,并且打印每一步训练的Loss。
模型保存和加载
通过pytorch可以保存和加载训练好的模型。
在 PyTorch 中,torch.nn.Module 模型的可学习参数(即权重和偏差)包含在模型的参数中(通过 model.parameters() 访问)。state_dict 是一个 Python 字典对象,它保存了模型每一层的参数。
# Print models state_dict
print("Models state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
打印结果如下
Models state_dict:
conv1.weight torch.Size([6, 3, 5, 5])
conv1.bias torch.Size([6])
conv2.weight torch.Size([16, 6, 5, 5])
conv2.bias torch.Size([16])
fc1.weight torch.Size([120, 400])
fc1.bias torch.Size([120])
fc2.weight torch.Size([84, 120])
fc2.bias torch.Size([84])
fc3.weight torch.Size([10, 84])
fc3.bias torch.Size([10])
通过state_dict 来保存和加载模型
# Specify a path
PATH = "state_dict_model.pt"
# Save
torch.save(net.state_dict(), PATH)
# Load
model = Net()
model.load_state_dict(torch.load(PATH))
model.eval()
也可以通过以下方式来保存加载完整模型
# Specify a path
PATH = "entire_model.pt"
# Save
torch.save(net, PATH)
# Load
model = torch.load(PATH)
model.eval()
总结
至此,pytorch的基本使用就介绍完成了,可以看出结合深度学习网络pytorch提供了非常好用的接口,帮助我们创建网络、加载数据、训练和部署等,极大的提高了深度学习的效率,后面我们将结合具体的例子对pytorch的使用做一个介绍。
深度学习
深度学习概念整理神经网络模型介绍 Pytorch使用介绍

