使用的代码
faster-rcnn.pytorch
重要参考
CNN目标检测(一):Faster RCNN详解
基於Resnet的Faster R-CNN網絡模型
重要参数
coco: 使用的数据集
coco数据集achor数量为3*4=12个
(P, Q):没有resize之前的原始图像大小.
(M, N): 输入到网络的图像, 是resize之后的图像大小.
重要数据
im_data:图像数据, size = ([batch, 3, M, N]), 由原始图像(P, Q)统一resize到(M, N).
im_info:图像信息,size = ([batch, 3]),保存的是 resize后的图像的H, W, 也就是上面图中的M, N以及resize的scale,scale = P/M = Q/N.
gt_boxes:gt box信息,size = ([batch, 50, 5]), 每张图片最多50个box, 每个box信息包含box的4个坐标和box的类别.
num_boxes:size= ([batch]), 记录每张图片有多少个box,因为在gt_boxes中每张图片都存储了50个box, 但实际上box数只有num_boxes[i]个,gt_boxes中box不够50的box信息全部填0.
整体结构
整体网络结构
2.整体代码结构
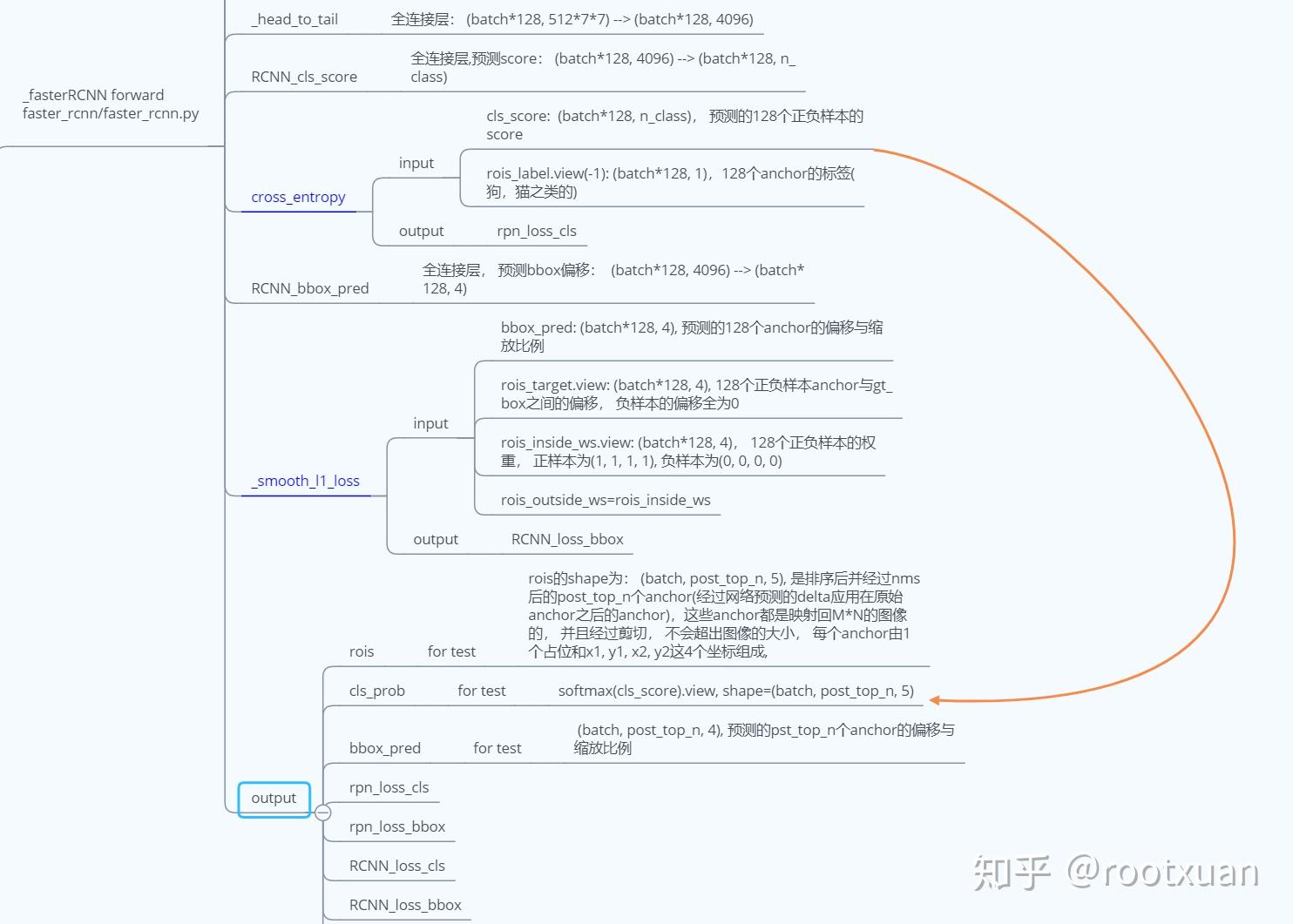
这里最重要的就是_fasterRCNN的forward过程:
i: RCNN_base, 卷积网络提取的图片特征, 输出为base_feat, shape=(batch, 512, M/16, N/16)
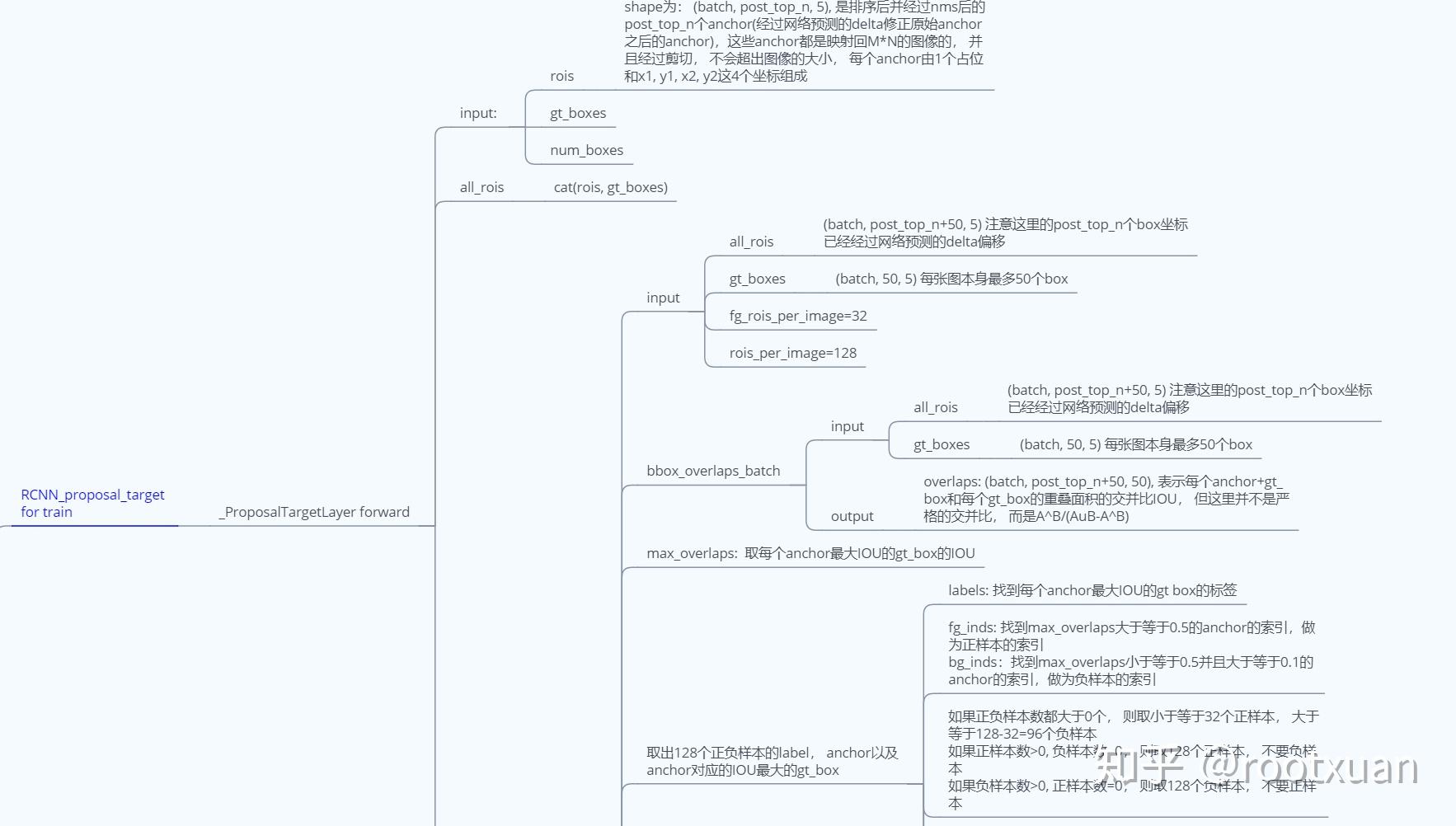
ii: RCNN_rpn, rpn网络, 计算rios、前景背景2分类loss和粗边框回归loss, 其中rois的shape=(batch, post_top_n, 5), 是排序后并经过nms后的post_top_n个anchor(经过网络预测的delta修正原始anchor之后的anchor),这些anchor都是映射回MxN的图像的, 并且经过剪切, 不会超出图像的大小, 每个anchor由1个占位和x1, y1, x2, y2这4个坐标组成。
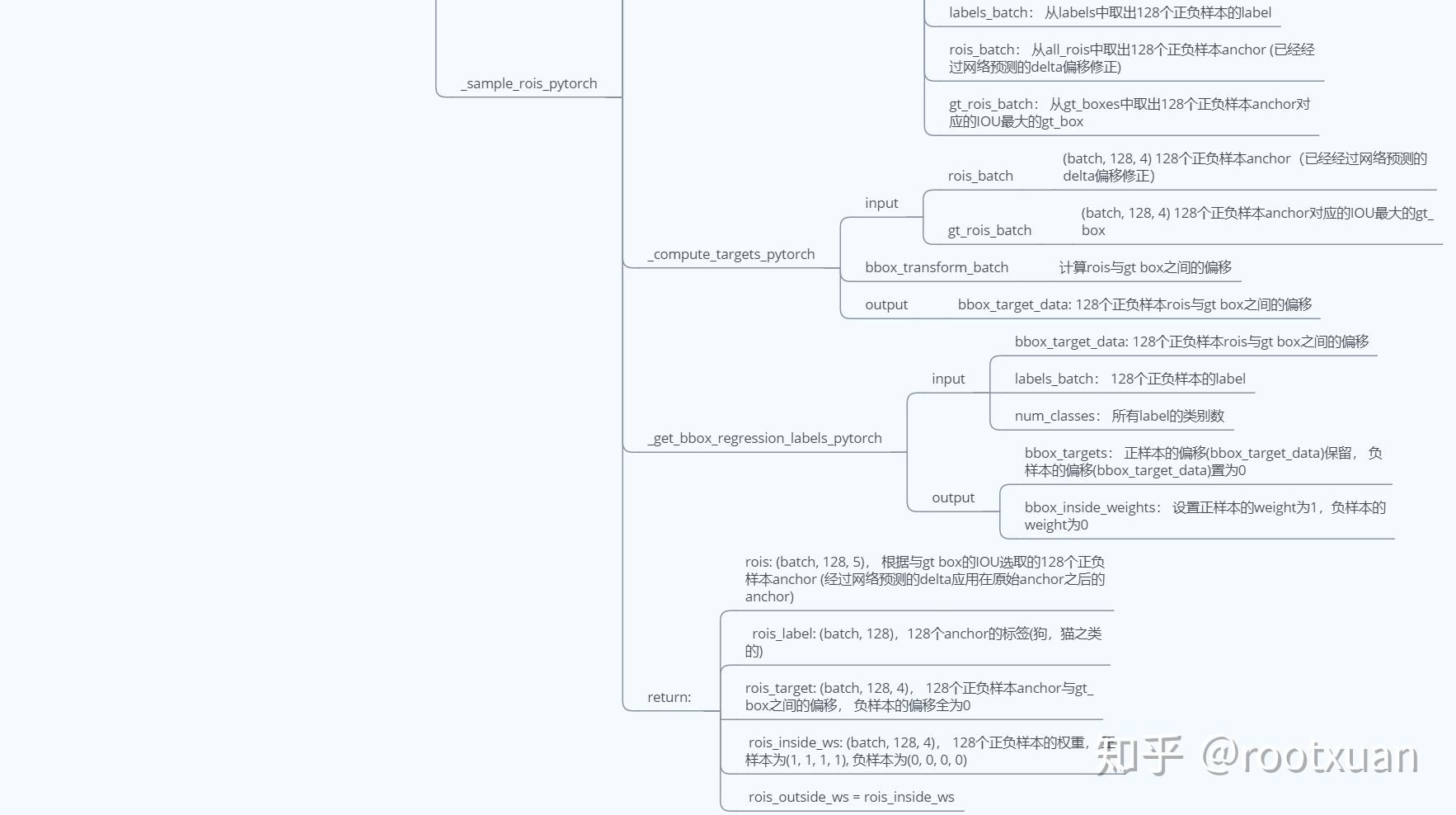
iii: RCNN_proposal_target, 本过程只有训练阶段有, 目的是得到128个与anchor有最大IOU的gt_box的label, 以及gt_box与anchor之间的偏移, 用作求类别loss和精边框回归loss.
iv: RCNN_roi_align, 使用roi_align方法将128个anchor每个都切成7x7的块, 输出为pooled_feat, shape=(batch*128, 512, 7, 7).
v: _head_to_tail, 全连接层: (batch*128, 512*7*7) --> (batch*128, 4096).
vi: RCNN_cls_score, 全连接层用做分类, 预测score, (batch*128, 4096) --> (batch*128, n_class), 并使用交叉熵求得预测的分类与第iii步得到的gt_box的label的loss.
vii: RCNN_bbox_pred, 全连接层, 预测bbox偏移: (batch*128, 4096) --> (batch*128, 4), 并使用smooth_l1求得预测bbox偏移与第iii步得到的gt_box与anchor之间的偏移的loss.
3.训练阶段的反向传播
根据2.ii、2.vi和2.vii求得的4个loss相加然后进行反向传播。
4.测试阶段的后处理
i: bbox_transform_inv, 根据2.vii得到的RCNN_bbox_pred 修正2.ii得到的rios.
ii: clip_boxes, 将 pred_boxes剪切在图像范围内, 超出边界的都剪切回图像内, pred_boxes个数没有变。
iii: 使用nms得到最终的rios和label.
代码细节
rpn网络
i: rpn整体结构
ii: rpn前置网络
iii: RPN_proposal
代码注释 proposal_layer.py / class _ProposalLayer
def forward(self, input):
# the first set of _num_anchors channels are bg probs
# the second set are the fg probs
scores = input[0][:, self._num_anchors:, :, :] # (batch, 12, M/16, N/16)
bbox_deltas = input[1] # (batch, 48, M/16, N/16)
im_info = input[2] # (batch, 3)
cfg_key = input[3]
pre_nms_topN = cfg[cfg_key].RPN_PRE_NMS_TOP_N
post_nms_topN = cfg[cfg_key].RPN_POST_NMS_TOP_N
nms_thresh = cfg[cfg_key].RPN_NMS_THRESH
min_size = cfg[cfg_key].RPN_MIN_SIZE
batch_size = bbox_deltas.size(0)
feat_height, feat_width = scores.size(2), scores.size(3)
shift_x = np.arange(0, feat_width) * self._feat_stride # =[0, 16, 32, ..., (feat_width-1)*16]
shift_y = np.arange(0, feat_height) * self._feat_stride # =[0, 16, 32, ..., (feat_height-1)*16]
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
return:
shift_x = [[0, 16, 32, ..., (feat_width-1)*16],
[0, 16, 32, ..., (feat_width-1)*16],
...
[0, 16, 32, ..., (feat_width-1)*16]]
shift_x shape=(feat_height,feat_width)
shift_y = [[0, 0, ..., 0],
[16,16,...,16],
...
[(feat_height-1)*16,...,(feat_height-1)*16]]
shift_y shape=(feat_height,feat_width)
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
ravel()函数和reshape(-1)函数是相同的
shifts =
[[0, 0, 0, 0],
[16, 0, 16, 0],
...
[(feat_width-1)*16, 0, (feat_width-1)*16, 0],
[0, 16, 0, 16],
[16, 16, 16, 16],
...
[(feat_width-1)*16, 16, (feat_width-1)*16, 16],
...
...
[0, (feat_height-1)*16, 0, (feat_height-1)*16],
[16, (feat_height-1)*16, 16, (feat_height-1)*16],
...
[(feat_width-1)*16, (feat_height-1)*16, (feat_width-1)*16, (feat_height-1)*16]]
shifts shape=(feat_width*feat_height, 4)
shifts 表示将原始(0,0)点的anchor需要经过怎样的平移可以得到M/16*N/16特征图上的每个点在M*N图像上的anchor,
比如说上面shifts中的
[[0, 0, 0, 0],
[16, 0, 16, 0],
...
[(feat_width-1)*16, 0, (feat_width-1)*16, 0]]
表示将(0,0)点的anchor左上角和右下角的x坐标向右移动, 而y坐标移动0, 则会得到第一行的点的anchor,
所以以上都是为了方便批量操作而做的工作
shifts = torch.from_numpy(np.vstack((shift_x.ravel(), shift_y.ravel(),
shift_x.ravel(), shift_y.ravel())).transpose())
shifts = shifts.contiguous().type_as(scores).float()
A = self._num_anchors # 12
K = shifts.size(0) # feat_width*feat_height
self._anchors = self._anchors.type_as(scores)
# anchors = self._anchors.view(1, A, 4) + shifts.view(1, K, 4).permute(1, 0, 2).contiguous()
anchors = self._anchors.view(1, A, 4) + shifts.view(K, 1, 4) # (K, A, 4)
anchors = anchors.view(1, K * A, 4).expand(batch_size, K * A, 4)
...
iv: RPN_anchor_target
代码注释 anchor_target_layer.py / class _AnchorTargetLayer
def forward(self, input):
...
total_anchors = int(K * A)
keep = ((all_anchors[:, 0] >= -self._allowed_border) &
(all_anchors[:, 1] >= -self._allowed_border) &
(all_anchors[:, 2] < long(im_info[0][1]) + self._allowed_border) &
(all_anchors[:, 3] < long(im_info[0][0]) + self._allowed_border))
# torch.nonzero输出非0元素的索引, shape=(N)
inds_inside = torch.nonzero(keep).view(-1)
# keep only inside anchors
# anchors: (N, 4), 在图片内的所有原始anchors(映射到 网络输入图像上的)
anchors = all_anchors[inds_inside, :]
# label: 1 is positive, 0 is negative, -1 is dont care
# labels shape=(batch_size, N)
labels = gt_boxes.new(batch_size, inds_inside.size(0)).fill_(-1)
bbox_inside_weights = gt_boxes.new(batch_size, inds_inside.size(0)).zero_()
bbox_outside_weights = gt_boxes.new(batch_size, inds_inside.size(0)).zero_()
anchors: (N, 4), 在图片内的所有原始anchors(映射到 网络输入图像上的)
gt_boxes: (b, 50, 5) 每张图本身最多50个box
overlaps: (b, N, 50), 表示每个anchor和每个gt_box的重叠面积的交并比IOU, 但这里并不是严格的交并比, 而是A^B/(AuB-A^B)
如果不算batch的话, overlaps =
[[v11, v12, v13, ..., v150],
[v21, v22, v23, ..., v250],
...
[vN1, vN2, vN3, ..., vN50]]
每一行表示一个anchor分别与50个gt box的IOU
overlaps = bbox_overlaps_batch(anchors, gt_boxes)
# 找到每个anchor最大IOU的gt box的IOU
# max_overlaps shape=(batch, N)
# argmax_overlaps shape=(batch, N)
max_overlaps, argmax_overlaps = torch.max(overlaps, 2)
# 找到每个gt box最大IOU的anchor的IOU, 也就是overlaps每一列的最大值
# gt_max_overlaps shape=(batch, 50)
gt_max_overlaps, _ = torch.max(overlaps, 1)
if not cfg.TRAIN.RPN_CLOBBER_POSITIVES:
# IOU小于0.3的为negative
labels[max_overlaps < cfg.TRAIN.RPN_NEGATIVE_OVERLAP] = 0
gt_max_overlaps[gt_max_overlaps==0] = 1e-5
overlaps: shape=(batch, N, 50)
如果不算batch的话, overlaps =
[[v11, v12, v13, ..., v150],
[v21, v22, v23, ..., v250],
...
[vN1, vN2, vN3, ..., vN50]]
每一行表示一个anchor分别与50个gt box的IOU
gt_max_overlaps.view(batch_size,1,-1).expand_as(overlaps) =
[[vmax1, vmax2, vmax3, ..., vmax50],
[vmax1, vmax2, vmax3, ..., vmax50],
...
[vmax1, vmax2, vmax3, ..., vmax50]]
其中vmax1是v11到vN1中的最大一个, 其他同理。
总共有N行。
A.ep(B): A和B相同的元素的位置置1, 不相同的置0
overlaps.eq(gt_max_overlaps.view(batch_size,1,-1).expand_as(overlaps)):
表示overlaps中gt box和哪个anchor的IOU最大, 那么其值就置为1, 其他的都置为0。
那么这时候就会出现某些行全是0的情况, 也就是50个gt box的最大IOU对应的anchor最多只能是50个,
那么其他anchor所在的行的值都为0
torch.sum(..., 2): 表示按行求和, 非全0的行sum的值就会大于0, 表示这个anchor是与gt boxes具有最大IOU的anchor中的一个
keep = torch.sum(overlaps.eq(gt_max_overlaps.view(batch_size,1,-1).expand_as(overlaps)), 2)
if torch.sum(keep) > 0:
labels[keep>0] = 1 #將与50个gt boxes具有最大IOU的anchor設置爲正樣本
# fg label: above threshold IOU
# 如果一个anchor与50个gt box最大IOU大于等于0.7的话, 将这个anchor设置为正样本
labels[max_overlaps >= cfg.TRAIN.RPN_POSITIVE_OVERLAP] = 1
...
for i in range(batch_size):
# subsample positive labels if we have too many
if sum_fg[i] > num_fg:
fg_inds = torch.nonzero(labels[i] == 1).view(-1)
# torch.randperm seems has a bug on multi-gpu setting that cause the segfault.
# See https://github.com/pytorch/pytorch/issues/1868 for more details.
# use numpy instead.
#rand_num = torch.randperm(fg_inds.size(0)).type_as(gt_boxes).long()
#随机选择一部分前景(sum_fg-num_fg个),置为-1(-1为无效框, 不是背景框),只保留num_fg个前景
rand_num = torch.from_numpy(np.random.permutation(fg_inds.size(0))).type_as(gt_boxes).long()
disable_inds = fg_inds[rand_num[:fg_inds.size(0)-num_fg]]
labels[i][disable_inds] = -1
# num_bg = cfg.TRAIN.RPN_BATCHSIZE - sum_fg[i]
num_bg = cfg.TRAIN.RPN_BATCHSIZE - torch.sum((labels == 1).int(), 1)[i]
# subsample negative labels if we have too many
if sum_bg[i] > num_bg:
#随机选择一部分背景景(sum_bg-num_bg个),置为-1(-1为无效框, 不是背景框),只保留num_bg个背景
bg_inds = torch.nonzero(labels[i] == 0).view(-1)
#rand_num = torch.randperm(bg_inds.size(0)).type_as(gt_boxes).long()
rand_num = torch.from_numpy(np.random.permutation(bg_inds.size(0))).type_as(gt_boxes).long()
disable_inds = bg_inds[rand_num[:bg_inds.size(0)-num_bg]]
labels[i][disable_inds] = -1
offset = torch.arange(0, batch_size)*gt_boxes.size(1) # [0, 50, 100, ..., (batch-1)*50]
# argmax_overlaps, shape=(batch, N), 是每个anchor最大IOU的gt box的index
# argmax_overlaps + offset.view(batch_size, 1).type_as(argmax_overlaps):
# 将每个anchor最大IOU的gt box的index分别加上0,50,100,...,(batch-1)*50
# 结果argmax_overlaps shape还是(batch, N)
argmax_overlaps = argmax_overlaps + offset.view(batch_size, 1).type_as(argmax_overlaps)
# gt_boxes.view(-1,5) shape = (batch*50, 5)
# argmax_overlaps.view(-1) shape=(batch*N)
# 所以gt_boxes.view(-1,5)[argmax_overlaps.view(-1), :] 则表示选择出与每个anchor最大IOU的gt box
# gt_boxes.view(-1,5)[argmax_overlaps.view(-1), :].view(batch_size, -1, 5) shape=(batch, N, 5)
# anchors: (N, 4), 在图片内的所有原始anchors(映射到 网络输入图像上的)
# bbox_targets: (b, N, 4), 每个anchor与其最大IOU的gt box的平移and缩放比例
bbox_targets = _compute_targets_batch(anchors, gt_boxes.view(-1,5)[argmax_overlaps.view(-1), :].view(batch_size, -1, 5))
# use a single value instead of 4 values for easy index.
# # https://www.zhihu.com/question/65587875
bbox_inside_weights[labels==1] = cfg.TRAIN.RPN_BBOX_INSIDE_WEIGHTS[0]
# https://www.zhihu.com/question/65587875
if cfg.TRAIN.RPN_POSITIVE_WEIGHT < 0:
num_examples = torch.sum(labels[i] >= 0) #前景背景样本总数
positive_weights = 1.0 / num_examples.item()
negative_weights = 1.0 / num_examples.item()
else:
assert ((cfg.TRAIN.RPN_POSITIVE_WEIGHT > 0) &
(cfg.TRAIN.RPN_POSITIVE_WEIGHT < 1))
bbox_outside_weights[labels == 1] = positive_weights
bbox_outside_weights[labels == 0] = negative_weights
# inds_inside: (batch, N), 所有在图像范围内的anchor的index
# total_anchors: weight*height*12, 所有的anchor数
# labels: (batch, N), 所有在图像范围内的anchor的label
# return labels: shape=(batch, weight*height*12), 所有的anchor的label, 不在图像范围的置为-1
labels = _unmap(labels, total_anchors, inds_inside, batch_size, fill=-1)
...
v: rpn loss
2. RCNN_proposal_target网络
3. RCNN_roi_align, roi align原理和流程这里先不介绍
4. 后置处理